(updated ) • Coding • 13 min read
Same Agent, Different Score: The Problem With Testing Non-Deterministic AI
What fifty Zork playthroughs taught me about evaluating non-deterministic systems
A few days ago I experimented with a couple local AI models by having them play Zork. They both got stuck in the maze, and the results were interesting: while one agent managed to score 35 points on a good run, most runs scored zero. The next steps in my plan was to give the agent structured tools such as maps, memory and breadcrumbs, and then test how they affected gameplay.
Before building tools and trying to measure their impact, I wanted a solid foundation to build on. That meant picking a model, but more importantly it meant having a benchmark I trusted. I expect finding the right approach with tools will require dozens of design decisions, and I need to be able to tell whether each one actually helps. Zork is an ideal testbed for getting evaluation right: runs are cheap (minutes, not hours), the score is unambiguous (the game tracks it for you), and every turn is logged, so you can replay exactly what happened.
I expected the work to be in running models and comparing scores. Most of it turned out to be in getting the ruler right. Even though I read a lot about evals in the context of applied AI to have a baseline expectation, nothing beats first-hand experience.
By now, everyone has heard remarks that LLM outputs are non-deterministic, to the point that it’s become a hand-wave: “results may vary.” However, when you actually try to make decisions based on aggregate scores from dozens of runs, the non-determinism stops being a footnote and starts being more tangible. The same model can score 40 on one run and 0 on the next. Different benchmark harnesses can make the same model look good or terrible depending on how they handle edge cases. And the only way to tell whether your numbers mean anything is to invest in the telemetry to audit them after the fact.
One caveat before the numbers: Zork has been on the internet for decades by now, and I bet at least some of these models have seen walkthroughs in training. I’m not expecting this experiment to measure general ability at playing text adventure games from a blank slate. What it measures is whether an agent can execute on a multi-step strategy it plausibly already has a model of, despite the non-determinism. That’s even more important for the tool-use experiments I intend to run next.
Two performance tiers
I expanded from two models to five, all running locally on the same RTX 5080 with 16GB VRAM. Each model played five independent games capped at 100 turns.
| Model | Params | Mean Score | Avg Latency | Notes |
|---|---|---|---|---|
| Gemma 4 26B | 26B MoE (4B active) | 19.0 (±16.4) | 6.5s/turn | Highest peaks, highest variance |
| Mistral Small 24B | 24B dense | 12.0 (±11.0) | 2.9s/turn | More consistent |
| Qwen 2.5 14B | 14B dense | 3.0 (±6.7) | 0.9s/turn | Fast but directionless |
| Gemma 4 E4B | 8B total (4B active) | 0.0 (±3.5) | 4.8s/turn | Too small |
| Phi-4 Reasoning 14B | 14B dense | 0.0 (±0.0) | 5.4s/turn | Couldn’t follow the format |
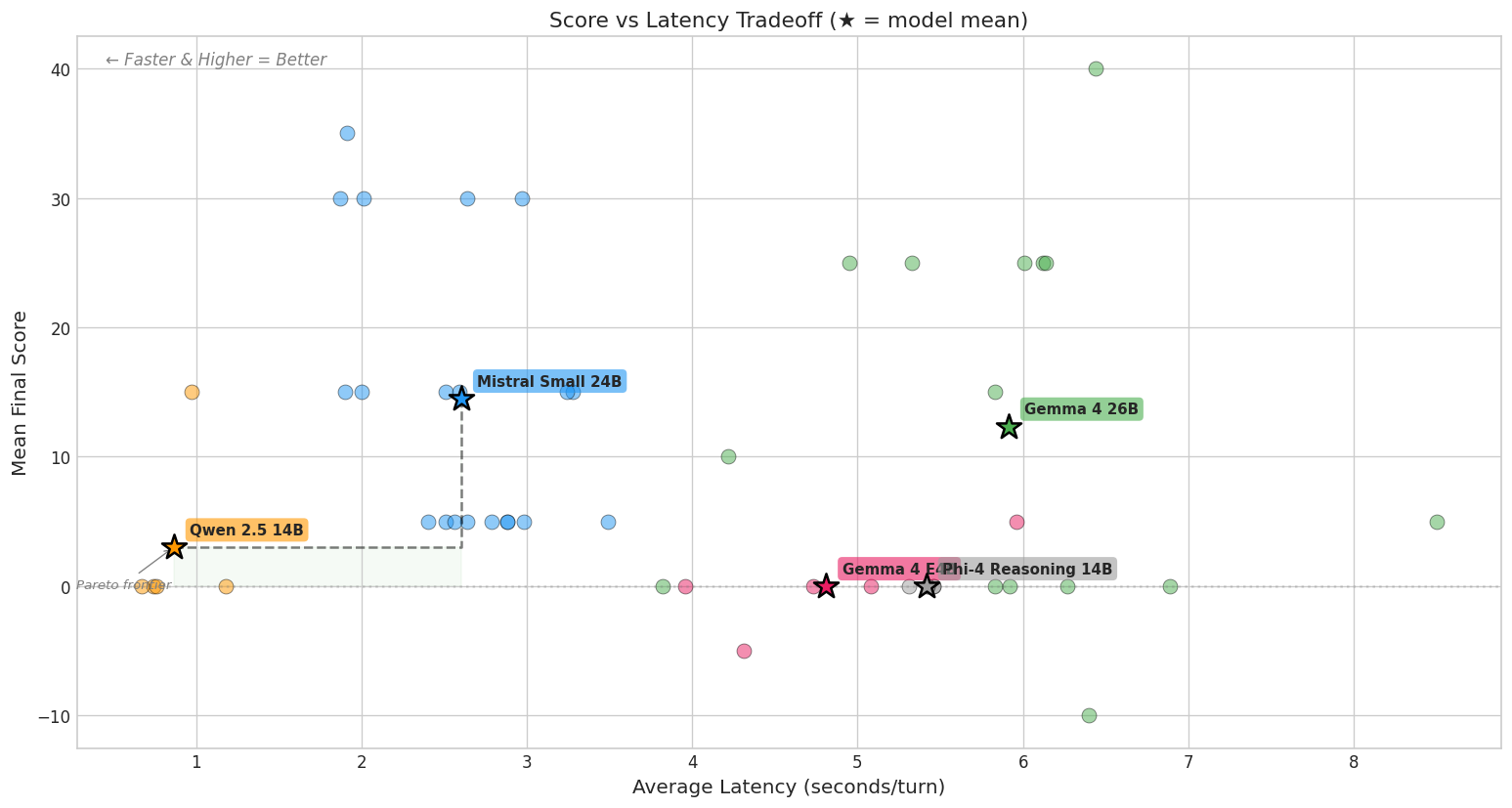
The first clear result: there’s no smooth spectrum. Three models score near zero, two score in the double digits. There’s nothing in between. This was already a win, because at this point I didn’t know whether I should expect a large gap in capabilities, and seeing statistically significant differences allowed me to start making decisions.
This seems to be one of the few results that survives the noise, and hints to a capability cliff. Gemma 4 E4B has one-third the parameters of its 26B sibling and drops from solving the cellar to scoring zero. Phi-4 Reasoning can’t even follow the JSON output format: every run looped within six turns. The gap between a model that “can play Zork” and one that “can’t” is significant, and it’s the only comparison where n=5 gives you statistical confidence.
The gap between the two models that can play? That’s where things get complicated.
The variance is not noise
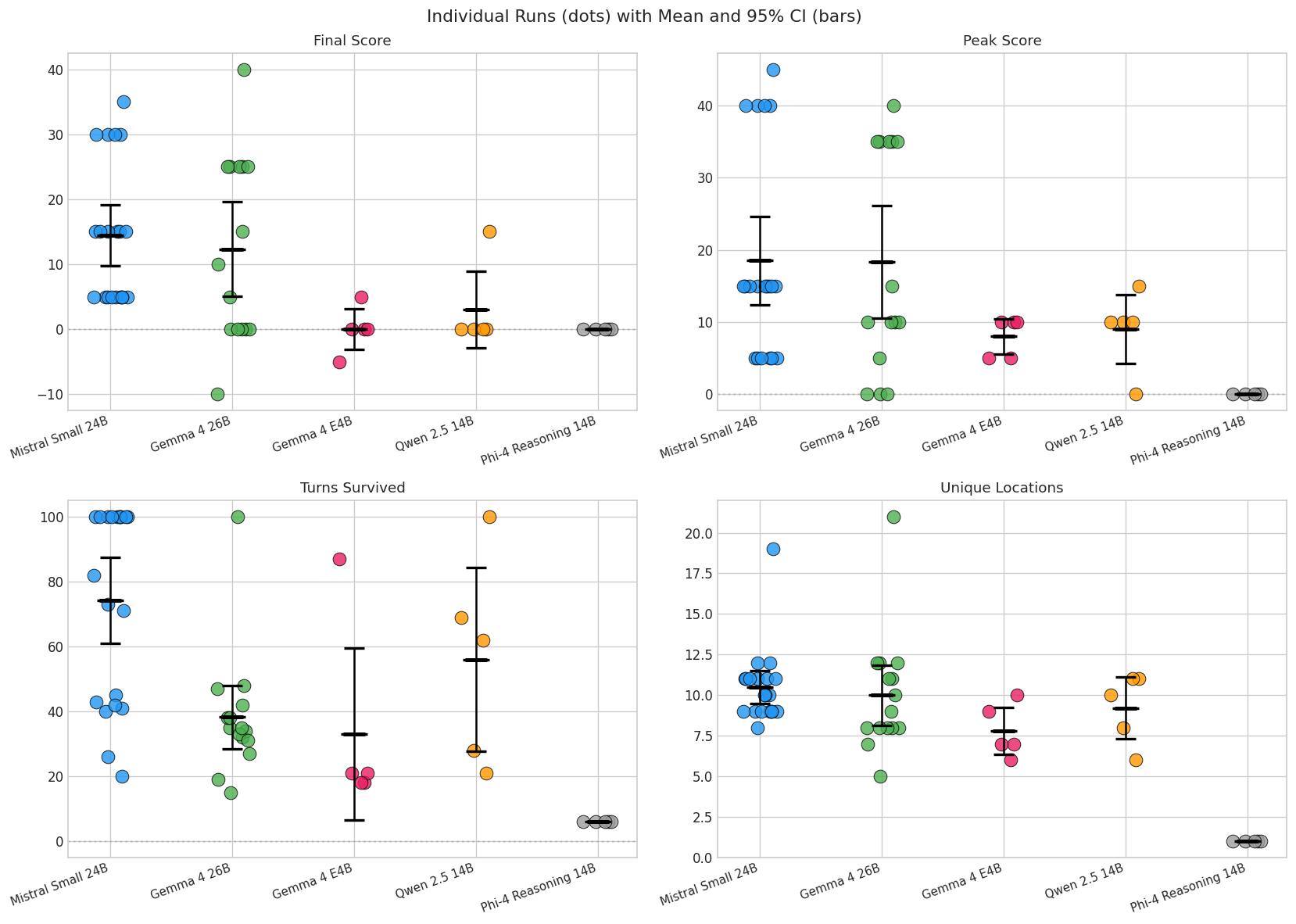
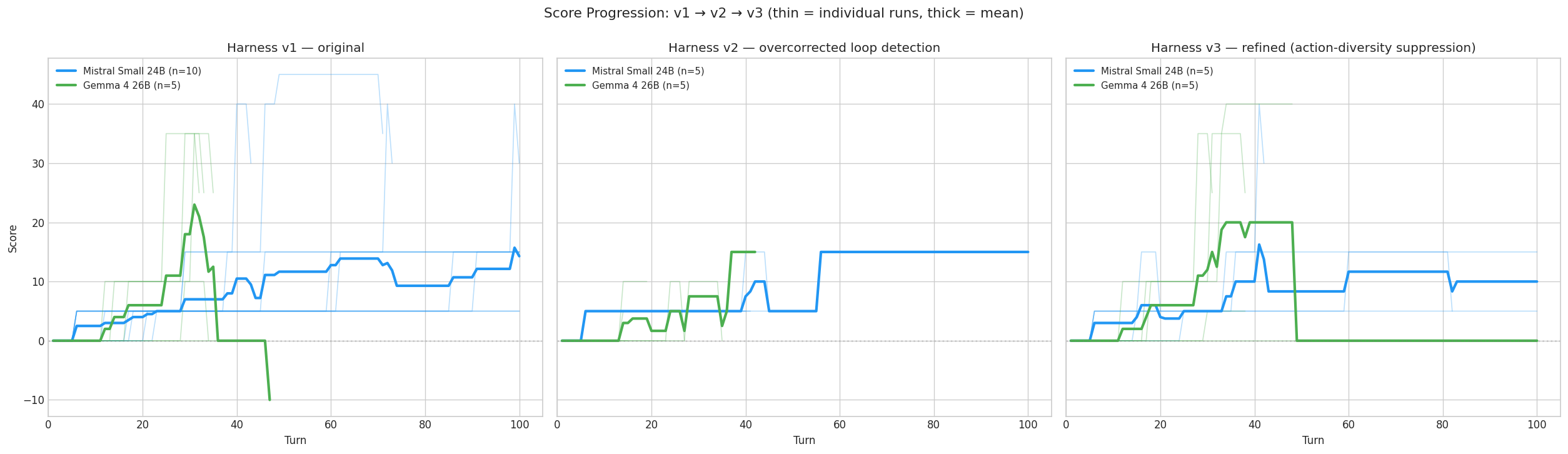
Look at Gemma’s individual scores: [25, 25, 0, 40, 5]. At first I thought that was just noise in measurement. When I started reading the game traces, it looked more like the model taking genuinely different strategic paths on each run.
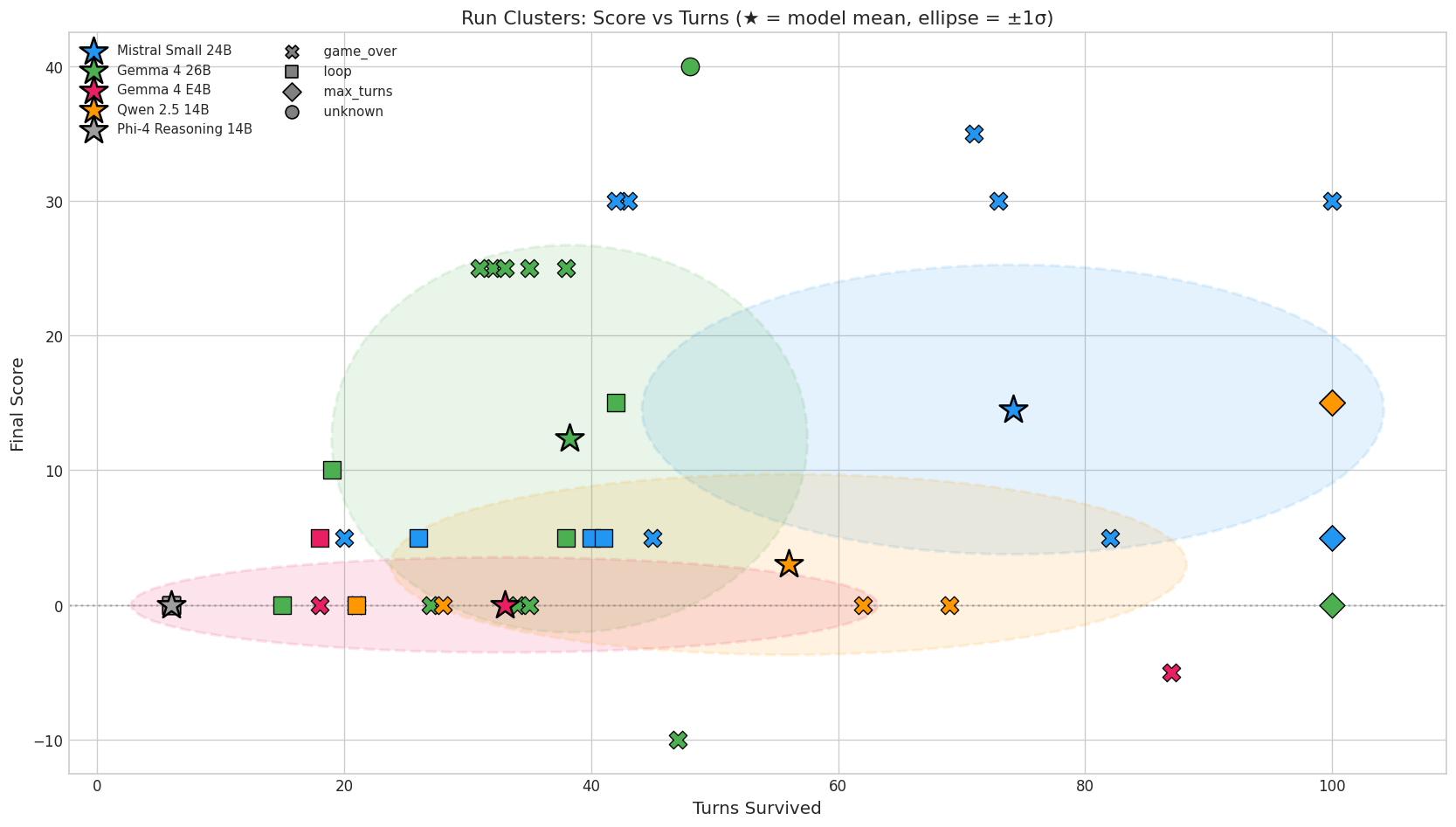
Gemma plays aggressively. It pushes into the cellar early, grabs items, and takes risks. When it works, it scores fast: 40 points in 48 turns in its best run. But it died in 80% of its runs, often in the dark or by falling into a pit. One run never even entered the house.
Mistral plays cautiously. It explores methodically, backtracks when confused, and survives much longer. But it plateaus. Its weakest runs scored 5 because it wandered the forest without finding a way in.
These aren’t noisy samples from the same distribution. They’re different behaviors sampled from different regions of the model’s probability space. Back when I was still struggling with getting Qwen to stick with English, I had set temperature to 0.2: low, but not zero. That small amount of randomness compounds across dozens of decisions into completely divergent playthroughs. This is aleatoric uncertainty: randomness inherent in the system, not reducible by collecting more data. More runs don’t make the distribution narrower. They reveal its shape, which is the actual information.
Sam Savage calls this the “flaw of averages”: plans based on average conditions are wrong on average, because the mean of a non-linear system doesn’t represent any actual outcome. Gemma’s mean of 19 is a score no individual run ever produced. It doesn’t tell you that Gemma either scored 25+ or crashed. Mistral’s mean of 12 doesn’t tell you that it rarely hit those highs but also rarely hit zero. The distribution is the result, not a nuisance to be averaged away.
If you’re choosing between them as agents, this matters. A cautious agent that reliably scores 15 is a very different tool than an aggressive one that scores 40 or 0, even if they average out similarly. For traditional evals, where the goal is to match a known expected answer, variance is noise you want to minimize. For agents navigating a complex space with branching consequences, variance is signal. It tells you the shape of what the agent might do, and that shape determines what kind of help it needs. That’s why pass@k metrics are valuable.
Put differently: if you only get one shot at a problem, you want Mistral. Its worst run was a 5, not a 0. If you can run the agent several times and keep the best result, you want Gemma: its ceiling is much higher even though most individual runs fail. The mean hides this entirely.
For deployments in the real world, these are the same two failure modes I have to consider. One agent type moves fast and occasionally nails it, but blows up when a step goes wrong. The other is so careful it runs out of budget before making progress. The tools you’d build to help them are different: the aggressive agent needs guardrails, the cautious one needs a push.
Three tries at honest measurement
This is where the deliberate investment in benchmarking paid for itself. I iterated through three versions of the harness, and the scores changed dramatically each time. And it wasn’t because the models changed, it was because of changes in the harness and benchmarking guardrails.
v1: Too lenient
The original harness only detected exact action loops: open mailbox, close mailbox, open mailbox, close mailbox. A model bouncing between the kitchen and the living room with different actions each time could wander for 80+ turns undetected. When the API timed out, the harness injected a fake action and kept going, corrupting game state. Under v1, Mistral looked strong (mean 19.5 across two batches of n=5) because its methodical wandering was never caught; Gemma’s mean came in at 13.0, dragged down by a catastrophic -10 run where injected actions corrupted the game state beyond recovery. Both numbers were the harness talking, not the models.
v2: Overcorrected
I added location-based loop detection, a token cap, and discarded runs on consecutive API errors. Scores cratered. Gemma dropped to 5.0, Mistral to 7.0. I initially took this as confirmation that v1 had been inflated.
But here’s the thing about non-deterministic evaluation: when your scores change, you don’t know if the system got worse or your ruler got shorter. I needed to look at individual runs to tell the difference.
The telemetry payoff
This is where an investment I’d made early on paid off. From the start, every turn logged the action taken, the location, the score, the model’s reasoning, and the latency, and some hardware statistics. I hadn’t needed most of this data. The benchmark “worked.” The charts looked reasonable. But now I could replay every termination decision.
Two of Gemma’s five v2 terminations were false positives. Both happened in the Kitchen. In both cases, the model had just scored points by entering the room, then systematically picked up every item: take bottle, take sack, open sack, take garlic, take food. Six turns, six unique actions, all productive. But the location detector saw “Kitchen” six times in a row and killed the run. It couldn’t distinguish “stuck in a room” from “thoroughly looting a room.”
I diagnosed this entirely from logs, without re-running a single game. If I’d been looking only at aggregate scores, I would have concluded that v1 scores were inflated and v2 was the honest version. The per-turn telemetry told a different story: v2 was punishing exactly the behavior I wanted to encourage. I keep coming back to this: you can’t tell whether a benchmark change is a fix or a regression from aggregate numbers alone. You need per-unit data or you’re guessing.
v3: Stuck vs. thorough
The fix was straightforward: before firing the location loop detector, check whether the actions are diverse. If at least two-thirds of recent actions are unique, the model is interacting with the environment, not stuck. This preserved all four legitimate terminations while sparing the two false positives.
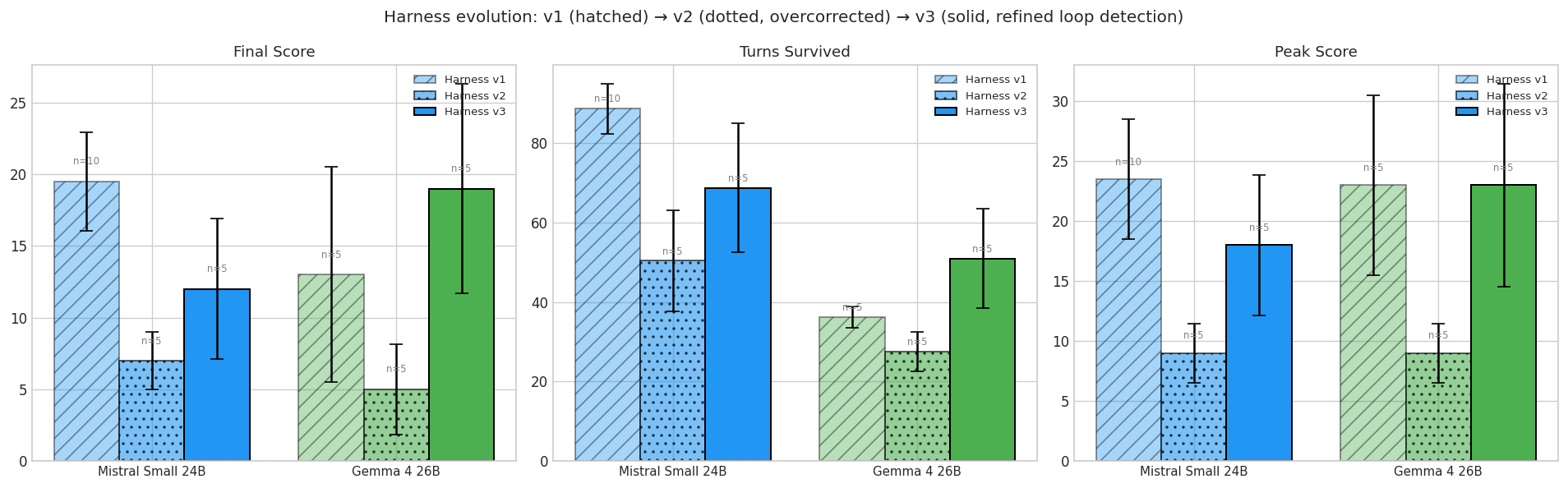
Under v3, Gemma recovered to 19.0 and Mistral to 12.0. They still aren’t statistically different: the variance is too high with n=5. But I trust the scores now reflect actual gameplay, not artifacts of the harness.
| v1 (lenient) | v2 (overcorrected) | v3 (refined) | |
|---|---|---|---|
| Gemma 4 26B | 13.0 ± 16.8 (n=5) | 5.0 ± 7.1 | 19.0 ± 16.4 |
| Mistral Small 24B | 19.5 ± 10.9 (n=10) | 7.0 ± 4.5 | 12.0 ± 11.0 |
The v1-to-v3 journey taught me something I keep relearning: the hard part of evaluating non-deterministic agents isn’t running them. It’s defining what counts as progress and what counts as being stuck. “Is the agent doing different things?” isn’t enough — it might be doing different things in a circle. “Is the agent in the same place?” isn’t enough — it might be productively working a complex room. You need both signals, and you need the telemetry to check your assumptions after the fact.
A note on the hardware cliff
One thing that shaped the experiment more than I expected: I run everything on WSL2 with an RTX 5080 (16GB VRAM), and WSL’s Hyper-V overhead eats about 1.5 GB. That doesn’t sound like much, but open-source models are released in size tiers designed to fit common GPU memory boundaries (8GB, 16GB, 24GB). Being just below a boundary doesn’t get you a slightly slower model. It drops you to the next tier down, which may not be capable enough for your task. The capability cliff from earlier can be caused by 1.5 GB of VRAM overhead just as easily as by model architecture. I have more to say about this than I can fit here, but the short version: “run it locally” sounds simple until your model choice is dictated by a hypervisor you didn’t choose.
The Troll is still the ceiling
Across every model, every run, every harness version, one fact hasn’t changed: no agent has ever fought the Troll.
The Troll guards the passage between the early game and the mid game. It requires selecting the right weapon from your inventory and attacking. Only one Gemma run, out of all the Gemma and Mistral playthroughs across every harness version, even reached the Maze beyond the Troll’s room. Every other run’s ceiling was the cellar.
The lantern is the key gate. Runs that grab it and descend into the cellar consistently score 25 or more. Runs that don’t top out around 15. Both capable models can reach the cellar. Neither has gotten past it.
This is where tools should finally make the difference. The Troll isn’t a reasoning problem. It’s an inventory management problem: the model needs to know it has a weapon, that the weapon is effective, and that it should fight instead of flee. That’s exactly the kind of contextual nudge that tool-assisted play can provide.
What I learned about evaluating agents
This is why I invested in benchmarking before building tools. Getting evaluation wrong at this stage would have meant building the entirety of tools and harness on top of numbers I couldn’t trust. Zork made the problems visible early and cheaply: a three-minute run instead of a three-hour production incident. If I had to distill what I learned into advice for anyone evaluating non-deterministic AI systems:
Run more than once. A single run tells you almost nothing. Gemma’s best run scored 40. Its worst scored 0. A one-shot eval would have given me either number and I’d have believed it.
Look at distributions, not means. The mean hides whether your agent is reliably mediocre or bimodally brilliant-and-catastrophic. For agents in complex environments, the distribution is the result: it tells you what the agent might do, and that determines what kind of help it needs.
Your harness is part of the system. The benchmark isn’t a neutral observer. Its loop detector, timeout policy, and fallback behavior all shape the scores. When results change, check whether the system changed or the ruler did. The Kitchen false positives would have led me to the wrong conclusion twice over if I hadn’t been able to replay individual turns.
Hamel Husain and Gergely Orosz make a similar argument from the enterprise-LLM side: the only way to know whether your evals are working is to read individual traces. I arrived at the same conclusion from a game-playing benchmark, which I take as evidence the problem isn’t domain-specific.
What’s next
I now have a benchmark I trust (though it took three tries) and two viable baseline models. Mistral Small at 2.9 seconds per turn gives me faster iteration; Gemma 4 at 6.5 seconds per turn has the higher ceiling. For building the ADK harness, I’ll use both: Mistral for rapid feedback and Gemma for measuring whether tools actually move the needle.
The question is straightforward: does tool access change the scores? The Python benchmark stays as the control. The honest harness will tell me.
Either way, the Troll is still waiting.