• Coding • 8 min read
Stuck in the Maze: Why AI Agents Can't Hold the Map
What a 44-year-old text adventure reveals about the limits of agentic reasoning
I was testing a local AI model this weekend when it started responding in Thai.
Not gibberish. Actual Thai script, mixed with Chinese characters. I’d asked it to play Zork, the 1981 text adventure, and it was doing everything except that.
This wasn’t what I set out to study. At work, I’ve had good results getting AI agents to respond to cloud alerts. A service throws an error, the agent reads the logs, traces the relevant code, and proposes a fix. But when a fix requires tracing a request from service A through a message queue to service B, then to service C’s database, the agent often gets lost. Not because it can’t reason about each piece. It can reason remarkably well about individual pieces in isolation. It just can’t hold the map.
I wanted to study that limitation in isolation. No pixels, no distributed systems, no production risk. Inspired by Ramp’s experiment getting Claude to play RollerCoaster Tycoon, I picked the simplest possible test of “can an agent find its way around?”: a text adventure.
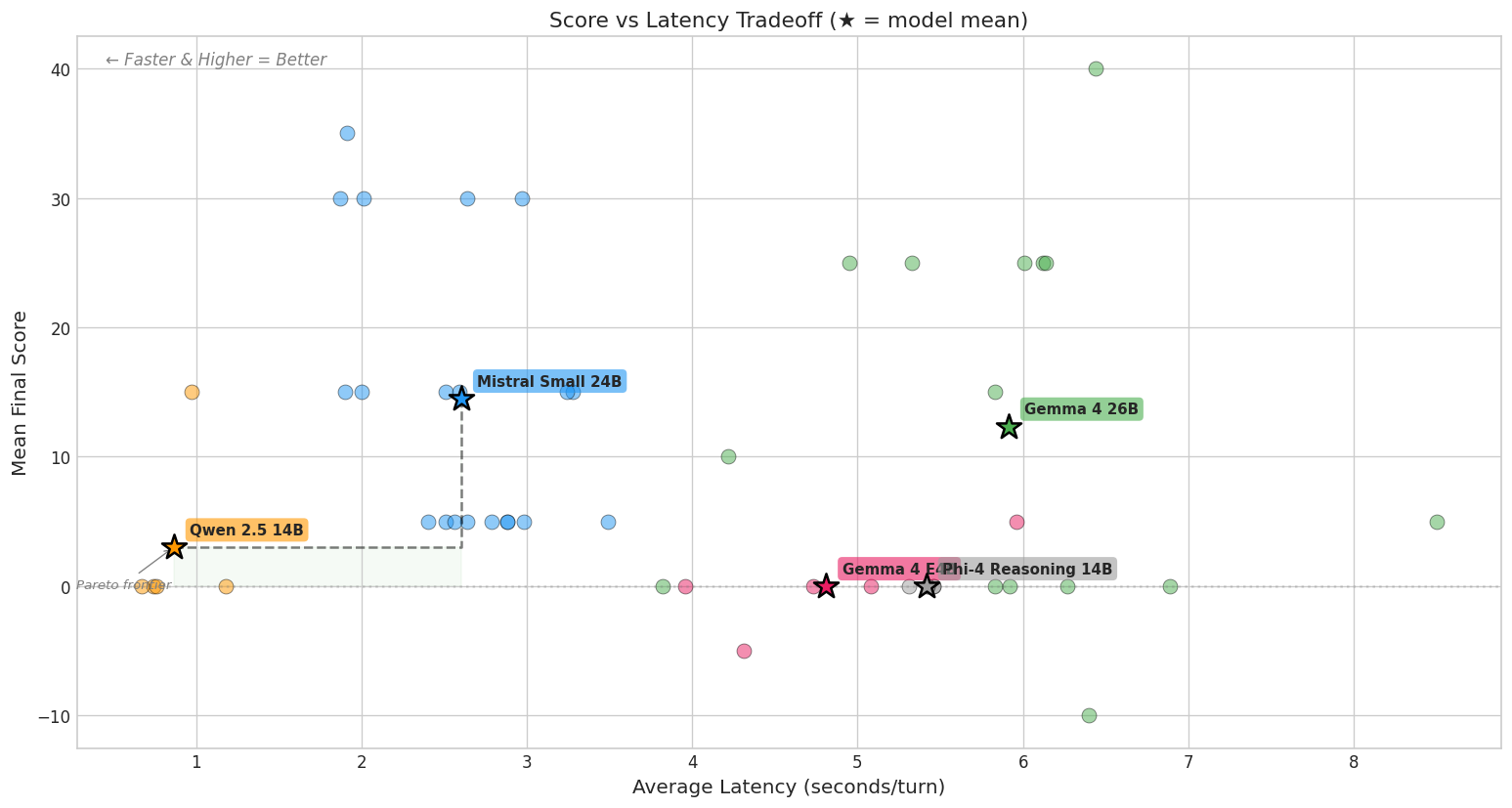
I also suspected that small local models would struggle with this far more than frontier reasoning models. That made the experiment more interesting, not less: if tools and scaffolding are what let frontier models succeed, then small models are the best stress test for whether your harness is doing its job.
The setup
Zork drops you in front of a white house. You explore rooms, collect items, solve puzzles, and try to score 350 points. The world is a graph of interconnected locations with descriptions, objects, and a few characters. It’s played entirely through typed commands like go north, take lantern, and open trapdoor.
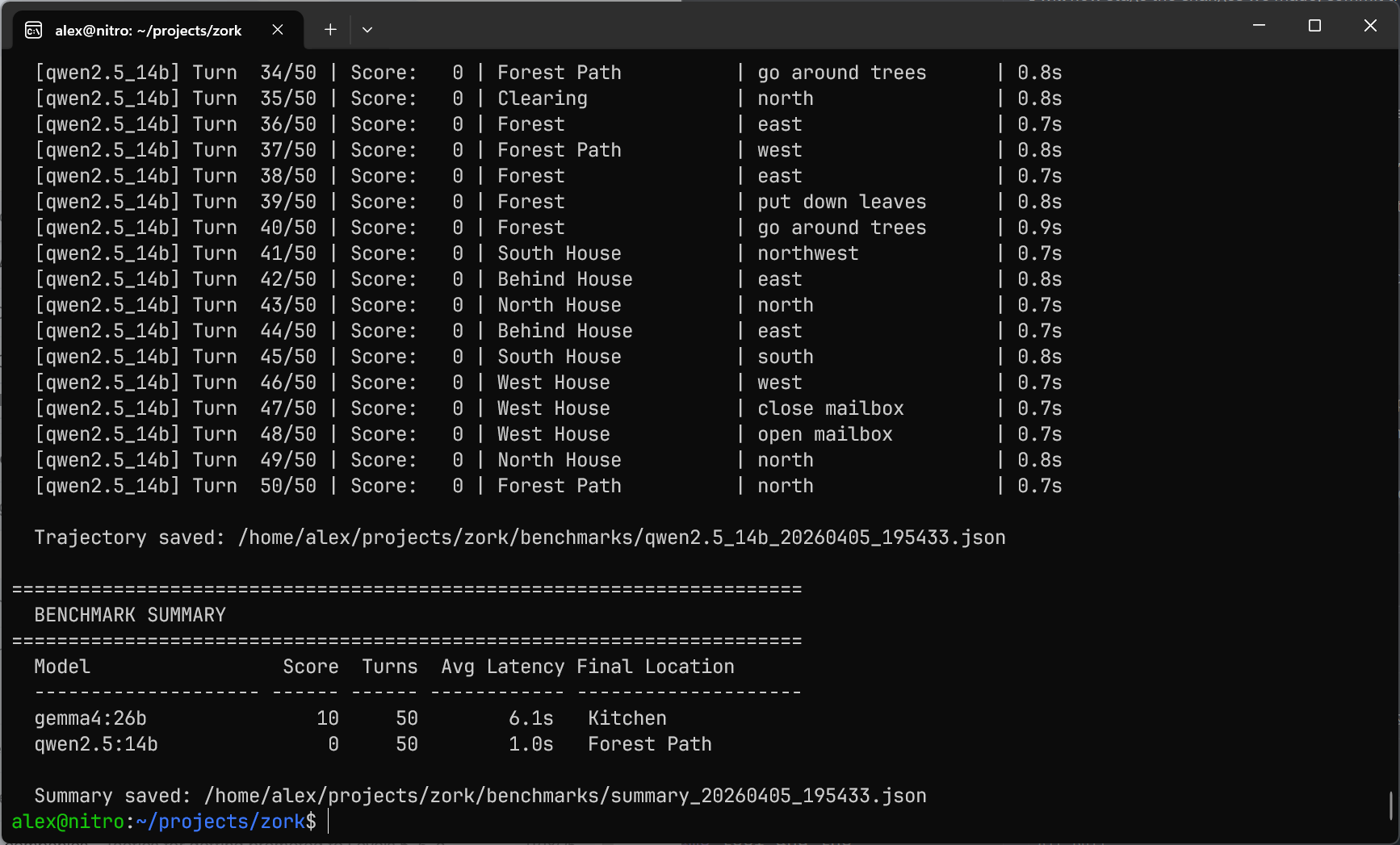
I wired together Jericho (Microsoft’s Python library that runs the original game file and exposes the state machine) with Pi Coding Agent, a TypeScript-based agent framework. Ollama running on an RTX 5080 with 16GB VRAM provided the model, and a custom bridge connected everything together, validating actions against Jericho’s state and logging every turn. I tested two models: Qwen 2.5 14B and Gemma 4 26B.
The goal was simple: tell the agent to play Zork. No hand-holding, no hints. Just: “you are an autonomous explorer, play the game.”
Day 1: why is my agent speaking Thai?
The first attempt was with Qwen 2.5 14B. I gave it a system prompt explaining it was an autonomous Zork player, handed it a tool to send commands to the game, and let it run.
It immediately broke character. Instead of playing, it started explaining how text adventures work. “In Zork, you typically want to explore your surroundings by using commands like LOOK and EXAMINE…” The model has been trained so aggressively on being a conversational assistant that it defaults to helping you play, rather than playing itself.
Fine. I tightened the constraints. Strict system prompt: “You are the autonomous player. Do not speak to me. Execute moves only. English only.”
That’s when it started outputting Thai.
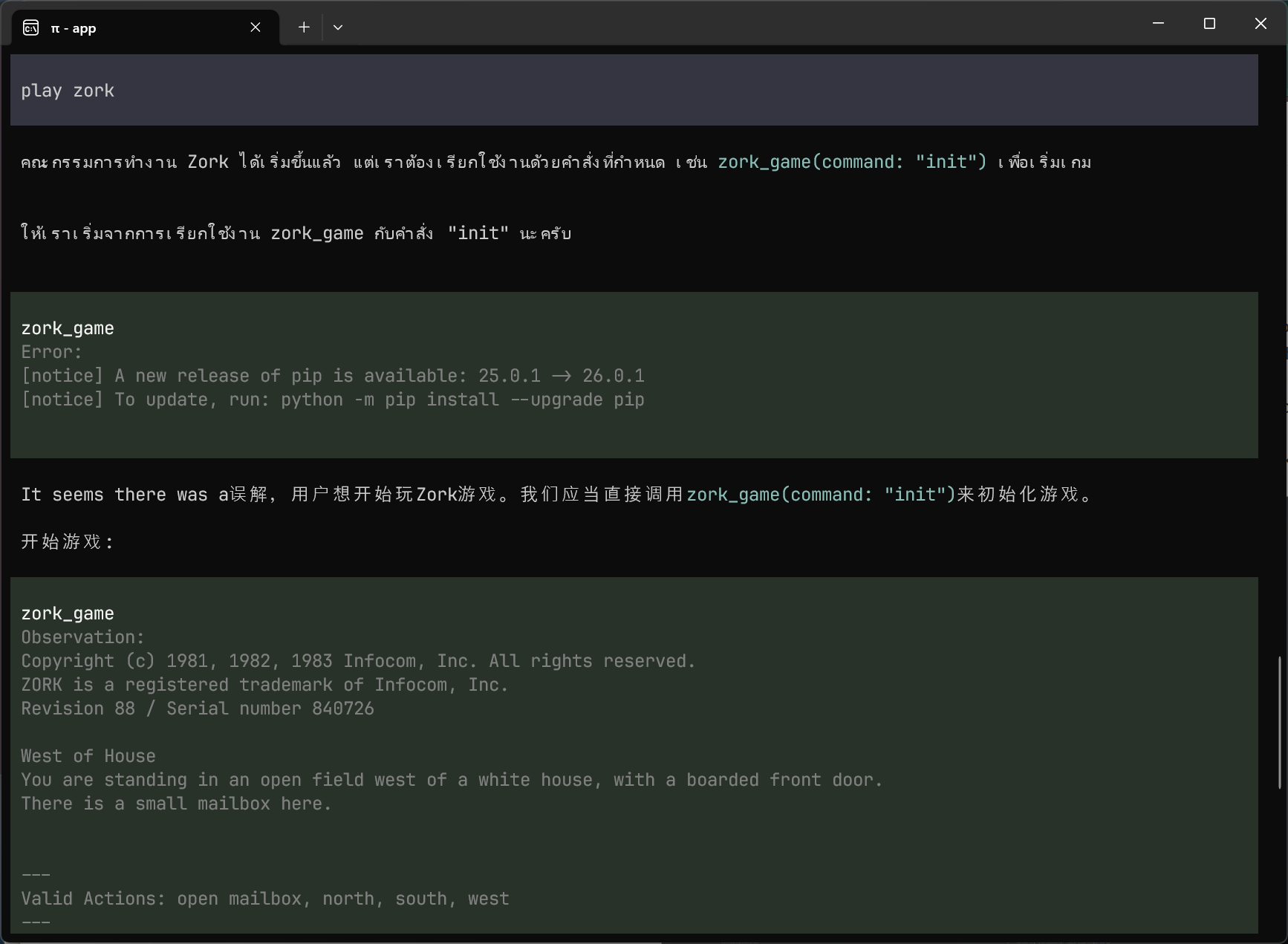
Actual Thai script, interspersed with Chinese characters. Fragments like 推进完毕 (roughly: “progress complete”). Under heavy “no chitchat” constraints, the model was reaching for high-probability tokens outside English. Qwen’s multilingual training means that when you suppress its English conversational patterns hard enough, other languages become the path of least resistance.
This wasn’t random hallucination. It was a pressure valve. And it was the most visceral reminder I’ve had that giving agents uncontrolled access to your systems requires more than a well-written prompt. If you can’t predict what language the model will respond in, you definitely can’t predict what commands it’ll try to run.
Day 2: the architecture pivot
I tried Gemma 4 26B too, Google’s mixture-of-experts model that had been released just two days earlier. It was more stable in English-only mode, which solved the immediate language problem. But swapping the model didn’t change the gameplay much. Both models scored similarly across runs: mostly 0 or 10 points, with occasional flashes of competence.
The real issue was architectural, not model selection.
I’d started with a static prompt template describing how to perceive the game, reason about it, and act. But rigid templates caused the model to output tool calls as plain text instead of actually executing them. The template was teaching it to perform the format, not use the tool.
The fix was to move the intelligence into the dynamic tool output. Every response from the game included not just the text but a state summary: current location, inventory, score, and valid actions. I also added a thought parameter so the model could reason inside the tool call itself, giving it working memory without triggering the conversational assistant pattern.
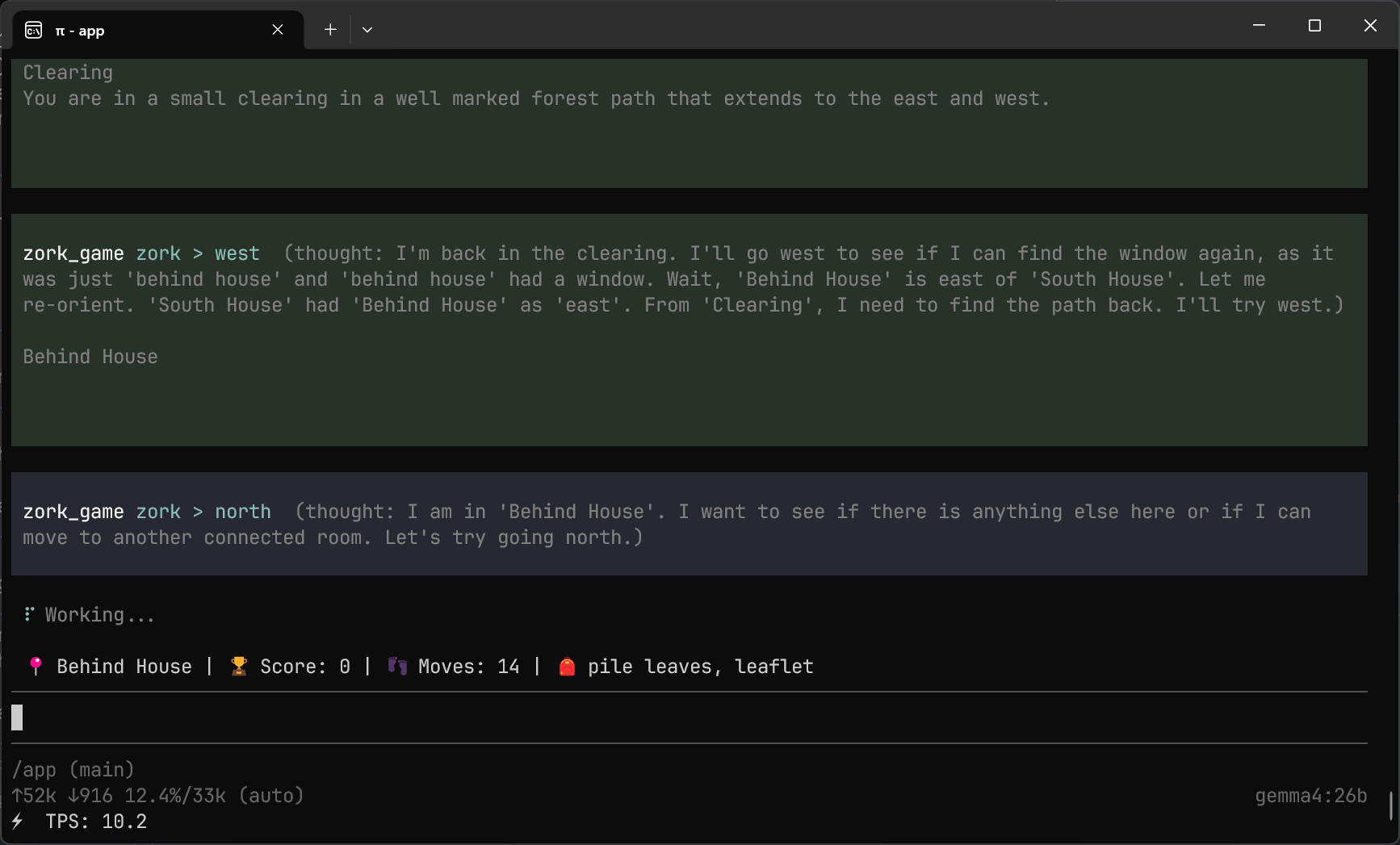
One unexpected tension: constraining the model too hard (temperature 0.0, strict bans on any non-game output) made it more reliable at calling tools but worse at actually playing. The creative reasoning needed to solve puzzles requires some flexibility. Over-constrained models would execute actions mechanically but make no progress because they never paused to think laterally.
Day 3: the maze
One run hit 35 points in 49 moves: it found the hidden cellar, lit the lantern, navigated the underground, and defeated the troll with the elvish sword. But that was a lucky outlier. What’s consistent across runs is the moment everything breaks: the maze.
Zork’s maze is legendary. It’s a set of rooms that all have the same description (“This is a maze of twisty little passages, all alike”) with exits that loop back unpredictably. It’s non-Euclidean: going north and then south doesn’t return you to where you started. Humans solve it by dropping items as breadcrumbs and methodically mapping connections.
The agent walked in circles. For over ten moves, it tried different directions, got the same descriptions, tried again. No breadcrumb strategy. No attempt to map what it had already seen. Each move was a fresh guess with no memory of the previous attempts.
It was stuck.
Why agents get lost
The maze failure isn’t surprising in hindsight, but it’s instructive. The agent wasn’t failing at reasoning. Each individual move was a reasonable attempt to escape. It was failing at spatial cognition: the ability to build and maintain a mental model of a connected space.
A few things made this worse than I expected.
Without a persistent world model, every turn is an isolated event. In one run, the agent found a jewel-encrusted egg (a high-value treasure) and immediately threw it down a grating. No sense that this object might be important later. No concept of consequences spanning multiple turns.
The tooling fought back in unexpected ways, too. Ollama’s repeat_penalty parameter, designed to avoid repetitive output, broke pathfinding above 1.1. The model became reluctant to output go north twice in a row, even when that was the correct path. A parameter designed to improve text quality was destroying navigational logic.
And the interface itself shaped behavior: running the agent through Pi’s chat UI made it more conversational and less autonomous. A headless Python loop with a tight execute-observe-act cycle and no chat played noticeably better.
The microservices parallel
Zork’s maze is a 44-year-old version of a problem I see at work: a graph of nodes that all look similar, where you can only see your immediate surroundings, and where the only way to make progress is to build and maintain a map as you go. Tracing a request through service A → message queue → service B → database C is the same kind of spatial reasoning challenge.
Frontier models with proper tooling handle this much better than my local 14B and 26B models did in Zork. But the pattern that makes them succeed is the same one that would fix the maze: external memory, explicit maps, state injection. The model doesn’t discover the topology on its own. The system provides it. The lesson from Zork isn’t that agents can’t navigate complex systems. It’s that they can’t do it without scaffolding, and the smaller the model, the more scaffolding it needs.
What’s next
This is where I am now: an agent that can sometimes play Zork, sometimes wanders in circles, and reliably gets stuck in the maze. The scores are modest, the tooling is rough, and neither model has a clear edge over the other.
But the experiment is pointing at something real, and I now have a harness to keep pushing. Next, I want to give my agents better tools: maps they can query, memory they can write to, breadcrumbs they don’t have to invent. I’m eager to see how much that changes the scores.
If you want to understand where your agents are getting lost, give one a text adventure. The maze will show you exactly where the reasoning stops and the flailing begins.