• Coding • 13 min read
Same Agent, Different Score: The Problem With Testing Non-Deterministic AI
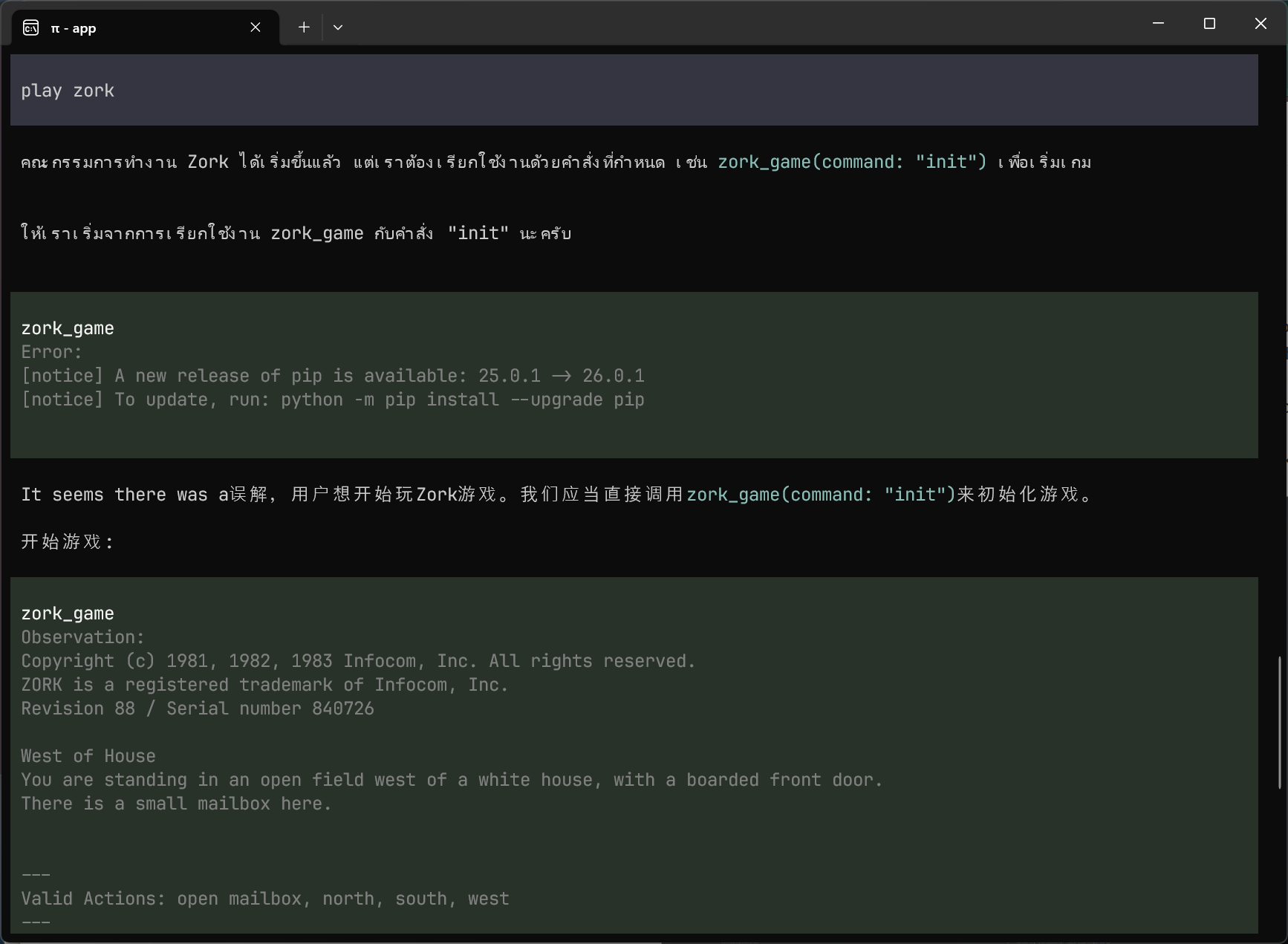
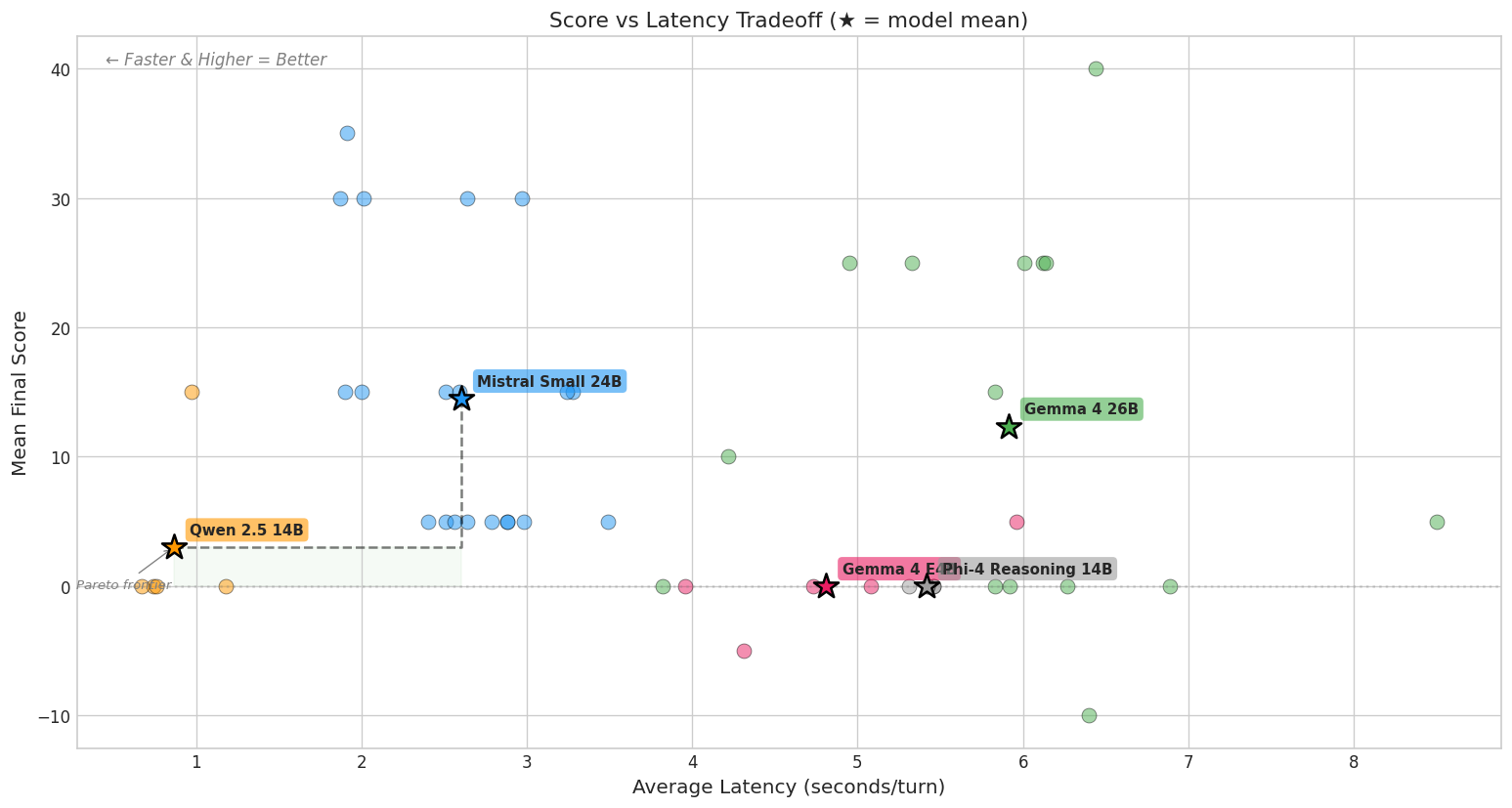
Before building tools for my Zork-playing agents, I needed a benchmark I could trust. I ran five local models through fifty playthroughs and discovered that the same model can score 40 or 0 on the same game. Getting honest numbers required three harness versions, structured telemetry, and a loop detector that learned the difference between stuck and thorough.