• Coding • 3 min read
What’s wrong with Milan’s Open Data initiative
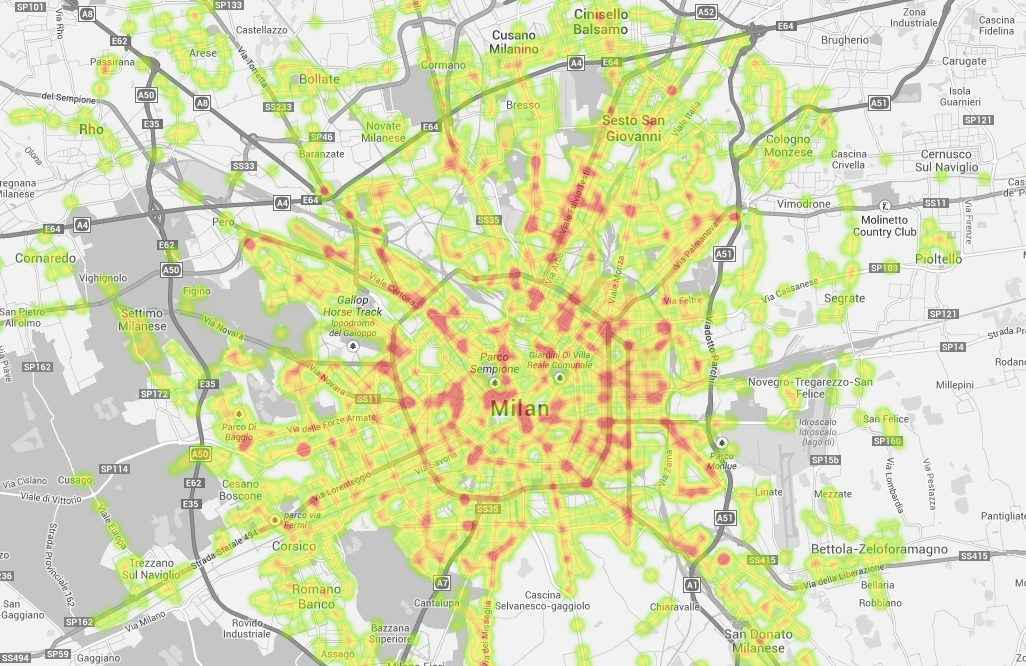
I spent some time playing with the Open Data published by the City of Milan, aiming to visualize public transport coverage. While I managed to create a heatmap, I was left unsatisfied by the data presentation and format. The initiative is promising but could be dramatically improved by adopting modern standards like GeoJSON instead of Shapefiles and including simple preview capabilities.