(updated ) • Leadership • 18 min read
The Velocity Paradox
Why 100x faster code doesn't mean 10x faster shipping
We’ve all been there. You sit down with an AI agent on a Saturday morning to hack on a side project and it feels like magic. Ten minutes in, you are blown away by how quickly the agent can turn even poorly organized thoughts into working prototypes. You feel like you could do this all day.
And clearly, many of us do: we’re rediscovering our passion for side projects, and every day a thousand bespoke ToDo apps are born, perfectly tailored to the unique needs of their creators.
At the same time, if you’re in an engineering leadership role, you’re also seeing your stakeholders dabble with agentic coding. They are shipping side-hustles on the weekend, and respectable work applications in an afternoon. Some of them might even look at you with ill-concealed suspicion. They want to know why their “pet feature” is stuck in a two-week cycle when they just whipped up a functional prototype over coffee.
And they aren’t entirely wrong. AI agents have been writing 100% of my code for several months now. Informed by the wins on my side-projects, I wanted to see how much faster we could build at work. During the holiday break, I spent a few hours having Claude write a non-trivial feature that touched our database, cloud infra, mobile app, and the embedded application that runs on our hardware devices at Quilt. What would have taken me a week to write took an afternoon to generate.
Yet it still took weeks to get it tested and merged.
It felt like strapping a rocket engine to a tricycle. Exhilarating, sure, but the road ahead is still full of potholes, and there’s a canyon where the bridge used to be. So why isn’t the 100x improvement in how fast AI can generate code moving the needle on how fast we can ship features and improvements?
Coding was never 100% of the job. But for those of us managing legacy debt, AI doesn’t just fail to solve our problems; it collides with them.
I’ve been at several conferences recently where I met leaders from “AI-native” companies, organizations founded in an age where agentic coding is the baseline. One founder told me they don’t do code reviews at all; their CI pipeline is the reviewer. Another gives agents full control of their production infrastructure. For those of us anchored to a culture that is older than even just two years, these practices feel reckless. Yet even more measured companies are rethinking the fundamentals. OpenAI recently pulled back the curtain with their Harness Engineering article, showing engineering re-architected around AI from the ground up.
For the rest of us, the gap between “generating code” and “shipping value” is becoming a chasm. We are stuck in the Unhappy Middle, where the cost of code is diminishing rapidly, but the cost of review and verification is skyrocketing.
The Unhappy Middle
To understand why the promise of 100x faster progress thanks to AI still feels like an illusion, we have to look at the two forces we’re being squeezed by.
On one side, we have the AI-Natives. These are companies and teams founded in the AI era. They have zero legacy debt, they can approach the craft of engineering with an open mind, and they use the same exact “boring” tech stacks the models were trained on. They don’t have to go out of their way to “integrate” AI; they are born out of it. They don’t have to refactor their code to support automated verification, they never knew a world without it.
On the other side, you have the companies with the slack to reinvent themselves. Shopify’s CEO made headlines when he declared that AI proficiency is now a baseline expectation and that teams must justify why a job can’t be done by AI before requesting headcount. Companies like that (or Google, I bet) can dedicate teams to rearchitect their codebase, tooling and processes and build the scaffolding that is required to make AI work at scale.
Then, there’s the rest of us. I call it the Unhappy Middle.
- We support live products and services, with customers trusting us and depending on us daily. The cost of failure is higher than a toy prototype. Unlike your ToDo app, you can’t just throw an agent at a problem and hope it doesn’t break your production environment.
- We have accumulated technical debt as we were racing towards product/market fit, and yet never had the resources to pay it back. We have to balance work on infrastructure and developer experience with business priorities like opening new product lines. Most of these target ambitious schedules which (you guessed right) require taking on additional technical debt.
- With the age of Zero Interest-Rate Policies well behind us, but not quite with the coffers of a larger company, we always have to be mindful of our runway, are constantly short-staffed and always “do more with less”.
In short, we have to balance the technical complexity of an established company with the reality of a startup. Our survival depends on crossing the chasm as quickly as possible. Not every team is here. If your stack is standard and your tests are green, you may already be seeing the gains. But if any of this sounds familiar, the path forward is harder. Here are some examples from my reality.
Bespoke Frameworks: from Asset to Dead Weight
Before AI, we may have optimized for human speed by building bespoke frameworks, custom boilerplate generators or domain-specific languages and abstractions. For many teams, these were their “secret sauce”: internal abstractions that helped teams move fast in 2022. They came at a price (typically, new engineers have to take some time getting comfortable with them), but they often paid off.
Today, those clever optimizations are anchors holding us back. AI agents are brilliant at standard React and Python because they’ve seen it a billion times. And, at the same time, they are completely illiterate in our proprietary and opinionated internals. Every time I ask an agent to work in our bespoke code, I’m paying an invisible tax: I spend a third of my time fixing hallucinations because our “clever” code isn’t in anyone’s training set. (I wrote more about why this happens in The Ghost in the Training Set.)
And you know what’s funny? That’s often why some of the best engineers I know are unimpressed by AI agents: they focus on the last time they saw Claude trip on a gotcha that’s specific to their codebase and ignore the fact that it can build flawless React in the blink of an eye.
Zero Slack
We know technical debt is there, we always wanted to increase test coverage, we defer refactoring for testability because we need to fit one more feature before the release cut. We know that frameworks need to be standardized to become “AI-hospitable.” But in the Unhappy Middle, you have zero slack. You’re always racing, either to hit product-market fit or to extend your runway, and “cleaning up” feels like a luxury you can’t afford.
This creates a painful tradeoff. In a side project, or a non-critical business app, failure is cheap. For a company with a legacy codebase, complex release processes and addressing user-critical needs, the stakes are considerably higher. Without the slack to build automated guardrails, we’re left with manual human review and auditing.
And that’s where the 100x speed gain from AI goes to die.
When Generation Outruns Verification
We often think of the craft of software engineering as composed of several loops, each covering a different stage of the lifecycle, from idea to product. A good visual to illustrate this is the slide below, from a talk Addy Osmani gave at LeadDev New York 2025.
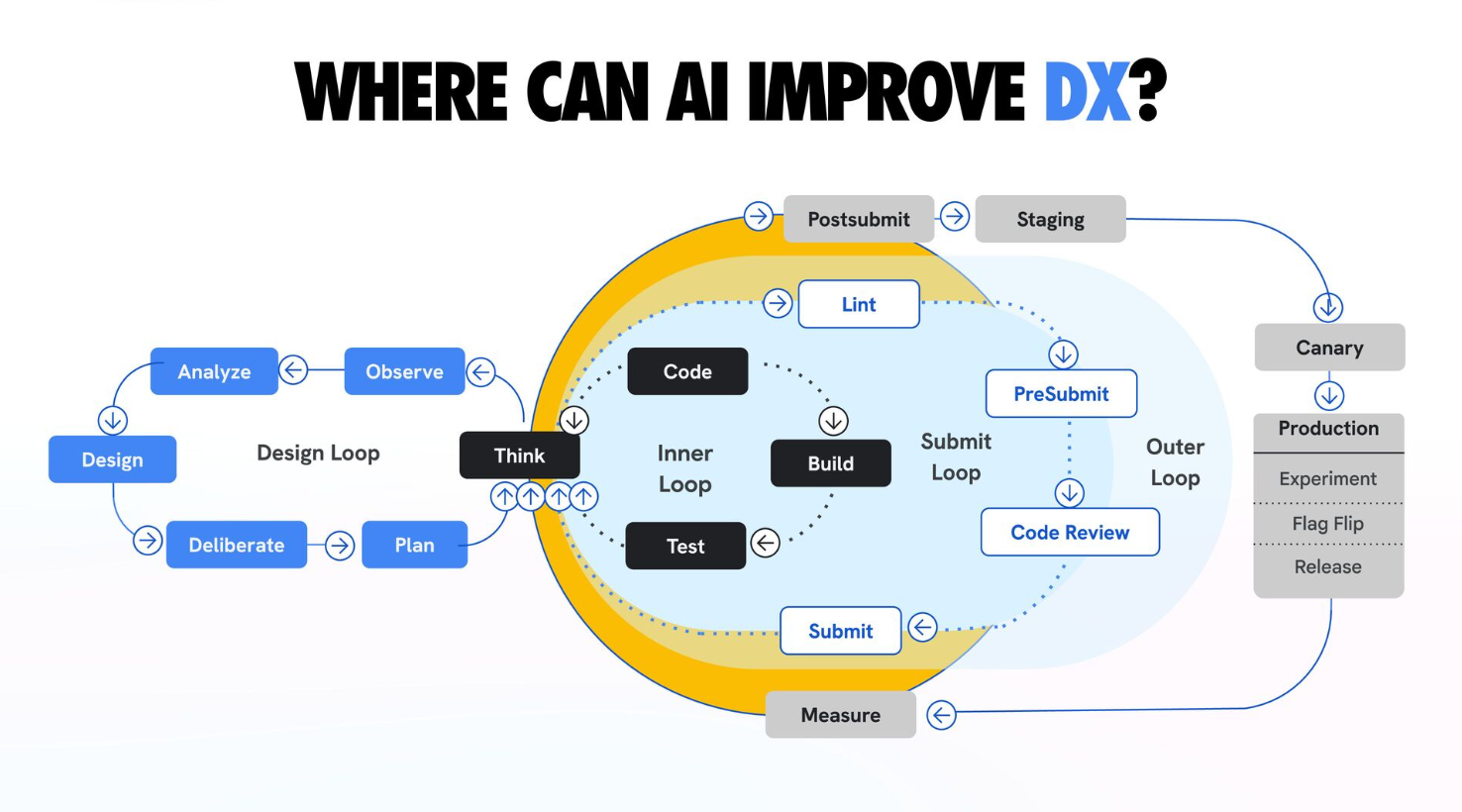
At the center is the Inner Loop: the tight cycle of thinking, coding, building and testing. This is where “flow” happens. Surrounding that is the Submit Loop, where your code goes through linting and code review, and the Outer Loop, where it finally gets deployed and gets tested in the real world.
The promise of AI-assisted engineering is to effectively collapse the Inner Loop. When an agent can “Think” and “Code” a cross-stack feature in a single morning, that center circle feels like it’s spinning at the speed of light.
But for those of us who are still in the Unhappy Middle, that loop is often broken before it even starts.
The Broken Inner Loop
The first problem teams are likely to encounter is a broken Inner Loop. Before AI, back in the day when code was expensive to write, tests were the first aspect of a healthy architecture to be sacrificed (or, in the best case scenario, deferred). When we skip writing tests, it’s common to end up with code for which it’s hard to write tests in the long run.
When you can’t give an agent a deterministic way to verify its own work, the feedback cycle doesn’t feed back into the AI, it feeds back into you. The agent isn’t looping, it’s just throwing code over the wall and waiting for you to tell it what happened.
In the best scenario you can imagine, the loop is closed by automation. The agent writes code, runs a test, sees the failure and iterates until it’s green. The feedback is a tight, self-correcting circuit.
Without a way to automate verification, you’re just making a mountain of work for yourself, or accepting to take an enormous amount of risk by shipping code that hasn’t been properly tested.
You were promised AI agents working for you to help you be more effective; instead, you are working for your agents. Not only is it not fun, it’s also a huge waste of your time because you are 100x slower than a software agent.
In my world, this isn’t just a metaphor. I feel it physically. At Quilt, we make hardware devices, and you can’t throw prompt engineering at the physical world. If a test requires me to get up, walk to a test bench and manually press a button, the inner loop isn’t just broken; it’s wide open.
And there are even worse consequences downstream.
The Slowing Submit Loop
Before AI agents were this capable, the high cost of writing code carried a hidden benefit. If an engineer spent two days wrestling with a complex feature, they effectively distilled a lot of context information into their brain. By the time they put a change up for review, the author was the deepest expert on those 200 lines of code.
That’s not how it works today.
As wonderful as the democratizing effect of AI agents is (they enable engineers to contribute well beyond their historical area of expertise), it comes with downsides.
If an agent can’t automatically verify its changes, and the author is not the most experienced engineer in the area affected by a change, the bulk of the burden of audit and review will shift to the reviewer.
On the average team, code reviews are assigned to the most experienced engineers in a given area or domain. In this new world, these folks are getting overloaded with more code to review. Worse, they can no longer assume that the author has the same depth of knowledge about the code that reviewers historically could take for granted.
At the extreme, this has multiple effects:
- Because the agent did the heavy lifting, the human author may have a shallower understanding of the “why” behind specific implementation choices.
- The reviewer is now receiving 10x more code, but with 10x less intent provided by the author. If the reviewer didn’t (or couldn’t) do a thorough review themselves, it’s 10x more code reviews of a higher intensity. Think more of a forensic audit than a style check.
- In a legacy codebase with bespoke frameworks, this can be extremely challenging. If neither the author nor the reviewer fully understands the “clever” choices the AI made, they can’t distinguish between valuable additions and hallucinations, and therefore are taking a high risk shipping this to production.
The practical consequences are tangible. Code ends up spending more time waiting for review than in development (this is what happened to my proof of concept I mentioned earlier). Your most experienced engineers struggle to be productive themselves because they are drowning in code reviews.
But the most worrisome part is what this does at an emotional level.
From Craftspeople to Janitors
If we take the patterns above to the extreme and let them fester without fixing them, then we are taking on a huge organizational risk by turning our most senior engineers into Janitors.
Instead of going to a challenging workday where, at the end, we experience the joy of having created something new, we now have to pore over someone (or, rather, something) else’s code to spot issues and problems. Some engineers feel like they are being paid to clean up AI hallucinations.
This can be deeply demotivating. No one likes being a linear bottleneck downstream of a stage that is accelerating at exponential speed. This is even more difficult at the speed this shift is happening, as many people are mourning the loss of the craft, made worse by simplistic takes about how the world of tomorrow needs fewer engineers.
I still deeply enjoy coding but I recognize that, even in the best of days, a lot of the code I wrote was boilerplate needed to wire together different application components. A very common micro-kitchen joke from my time at Google was that we were all just highly-compensated Protocol Buffer translators.
We miss the 20% of the code we used to write that was high-leverage and intellectually interesting, and forget the other 80% that was toilsome and repetitive.
From Janitors to Gardeners
If you treat every AI-generated PR like a chore to be cleaned up, you are a Janitor. To move fast in a legacy codebase, we need a considerable change in mindset. If you allow me another metaphor, we need to start treating our codebase less like a perfect jewel to polish and more like a plot of land to tend to.
I’ve been thinking about this metaphor for a while. As you scale an organization, you can’t afford to micromanage; you provide structure and support so that decisions happen organically, aligned to what the business needs. The same applies to codebases.
Playing into the metaphor, a gardener may focus their attention on a few things:
Tending the Soil
- Hospitable Ground — Transforming AI-Hostile codebases into an AI-Hospitable playing field requires investing in reducing technical debt, so that AI can’t hide behind it. It may mean moving away from bespoke patterns that routinely trip up agents, or making them work reliably. It means standardizing on a well-defined and documented set of abstractions, instead of having 3 different ways to set up an API server because we never finish migrations every time we deprecate an old pattern.
- Nutrient-Rich Soil — Agents are great at brute-forcing their way to a workable solution, but very often they struggle because the codebase lacks information beyond the code itself. Code written in haste often lacks documentation about “Intent” and the “Why” we made decisions. If we don’t expose context about tradeoffs and historical decisions, our agents are operating with limited information. Well structured
agents.mdfiles are a good start. Checking in architectural guidelines and making them discoverable is increasingly paying off. Ironically, if you keep your design docs locked in Google Docs, your agent is blind to them (hey Google, when can we have MCP access to Google Docs?)
Scaffolding and Direction
- Scaffolding — You don’t tell plants how to grow and expect them to listen; you provide scaffolding and support. In software, this can be types, interfaces and architectural boundaries. Well crafted designs that reduce coupling and abstract complexity behind well-defined interfaces are how you give agents a way to grow that is aligned to what you need.
- Resilience — Automated tests, lint checks and verifications are much more helpful for AI agents than they are to humans, as they enable both faster iteration speed and more confidence in the review stage of the submit loop. In the gardening metaphor, this is akin to the sturdy fencing that protects your plants from critters.
I find it ironic that many of the principles above are ones that practitioners have been advocating for under the banner of clean code, test-driven development and many others. We might callously shrug at the idea that we struggled to adopt them for the sake of our human co-workers and are now prioritizing them for the sake of our AI-agents. But the truth is that in the last decade, writing effective tests and good documentation cost us time: the time to think about them, and the time to type them. With AI agents being this capable, the typing cost is approaching zero. What remains is the thinking, and that was always the valuable part.
Building the Dark Factory
By now, it should be obvious that if we use AI only to automate the “Coding” stage of the development loop, we may not only struggle to make our team more effective, we may even hurt their effectiveness.
In the same talk by Addy Osmani I referenced earlier, he goes on to show several areas where AI can be effectively adopted to improve developer experience. In my day-to-day work, I’ve had considerable success using AI agents to troubleshoot bug reports and infrastructure alerts from our production fleet. The gains are real.
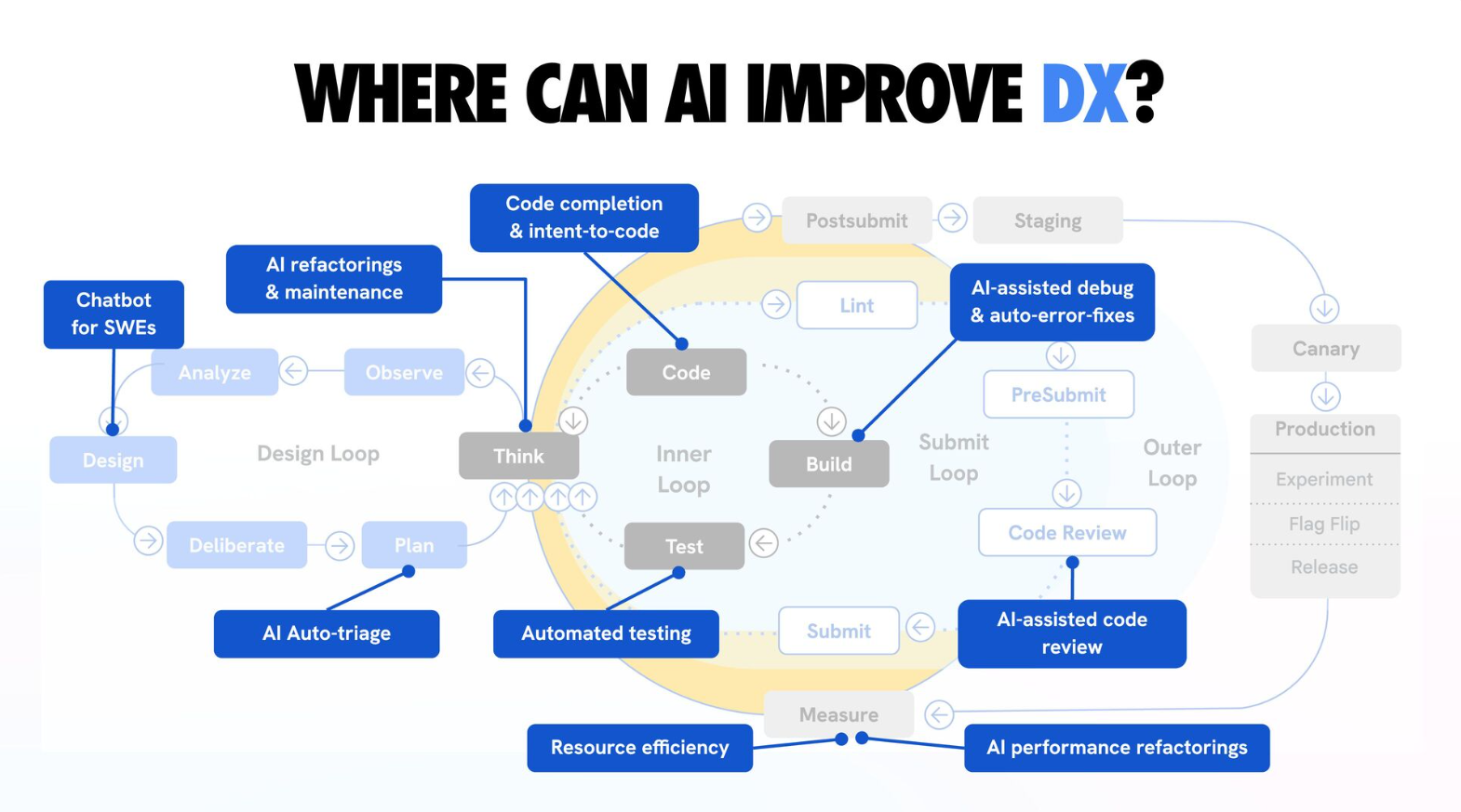
There is a growing conversation in engineering circles about “Dark Factories”: fully automated systems that run without human intervention. In the age of AI, our job is no longer to write the code; it’s to build the factory that builds the code.
Some high-leverage areas to start:
- The Verification Machine — Good test infrastructure should be the top priority. Well-written tests enable AI-agents to have much faster inner loops, but they also greatly help with faster code reviews. With good test scaffolding, you don’t just ask “Will this code work in this scenario?” You can ask an agent to demonstrate the expected behavior via a unit test.
- Address common tripping hazards for agents — You likely have a few areas where agents routinely struggle. Don’t just scoff when that happens, and use it to say “AI isn’t quite there yet”. Ask yourself why agents are struggling. Is it because of inconsistent patterns? Lack of context or documentation? Because your bespoke framework requires 1 year of experience in your own codebase to master? Making sure agents don’t make the same mistake twice should be part of our responsibilities.
- Reducing human dependencies for mechanical tasks — Invest in building reliable automated end to end tests that rely on production-like observability to spot issues and regressions. Wherever manual testing is required, ask yourself “what would it take for this test to happen automatically?” In a hardware company like Quilt, this means augmenting our ability to perform more tests in software.
- The Lights-Out Goal — Aim to have a “Submit Loop” so robust that if tests pass and the architectural boundaries are respected, the code is “shippable” by default. Even if that goal feels unrealistic (e.g. for code that is security-critical or that runs on devices that are hard to recover), ask yourself “What would it take for me to be 100% confident in a change without needing to review it?”
A word of warning: don’t confuse building the factory with building more features. If you ship 10x more features without correspondingly improving your infrastructure, you’re taking on a compounding liability. If AI agents today are enabling you to move even just a bit faster than yesterday, aim to put some of those velocity gains towards your scaffolding, instead of putting everything on more features.
Crossing the Chasm
The Unhappy Middle is a trap, but it’s also an opportunity to rethink what engineering leadership looks like.
This requires a fundamental shift in our ego as developers. Instead of ‘pwning’ the agent every time it trips on our proprietary abstractions, we need to ‘own’ our codebase and make it more AI-hospitable. If the smartest AI in the world can’t understand your code, it might not be the AI’s fault, but it might be a sign that our “cleverness” has become our biggest liability.
If we don’t cross the chasm quickly and change our mindset about how we write software, we risk being buried under our own AI-generated slop. The first step is to stop prioritizing just features as our primary output and start prioritizing the speed and accuracy of the factory.
It is notoriously hard to get organizational buy-in to address technical debt. The key is to reframe: this isn’t about “cleaning up” to pay off debt, it’s about investing in tooling to accomplish 10x velocity.
And even then, there are harder questions ahead. If you actually succeed in building the “factory,” you’ll quickly find that the technical bottleneck has evaporated, only to leave you with an organizational one. A 10x software factory is effectively useless if it’s embedded in a 1x decision-making process. And it is possible that we are approaching a Great Filter-like event for companies in the business of software — one that separates those who adapt from those who drown. But those are topics for another day.
For now, the goal is clear: stop just auditing lines of code and start building the systems that define the future of our industry.
Let us begin.
Update — March 2026
I explored the “1x decision-making process” problem further in Permission Structure.