(updated ) • Coding • 14 min read
The programming puzzle that landed me my job
Back in 2011, as I was getting a bored with my job and I started looking for new options. During my search, my friend Daniele (with whom I had built Novlet and Bitlet years before) forwarded me a link to the careers page of the company he was working for at the time, ITA Software.
While Google was in the process of acquiring ITA Software, ITA still had a number of open positions they were looking to hire for. Unlike Google, however, they required candidates to solve a programming challenge before applying to engineering roles.
The problems to solve were surprisingly varied, ranging from purely algorithmic challenges to more broadly scoped problems that still required some deep technical insight. As I browsed through the options, I ended up settling on a problem that intrigued me because I thought it resembled a problem I might one day wanted to solve in the real world and seemed to try to test both the breadth of my knowledge (it required good full stack skills) as well as my understanding of deep technical details.
I have good memories of the time I spent investigating this problem and coming up with a solution. When I was done, I had learned about a new class of data structures (suffix trees), gained a deeper understanding of Java’s internals. A year later, I got a job offer due in part to this puzzle.
The Problem Statement
The brief for the challenge was the following:
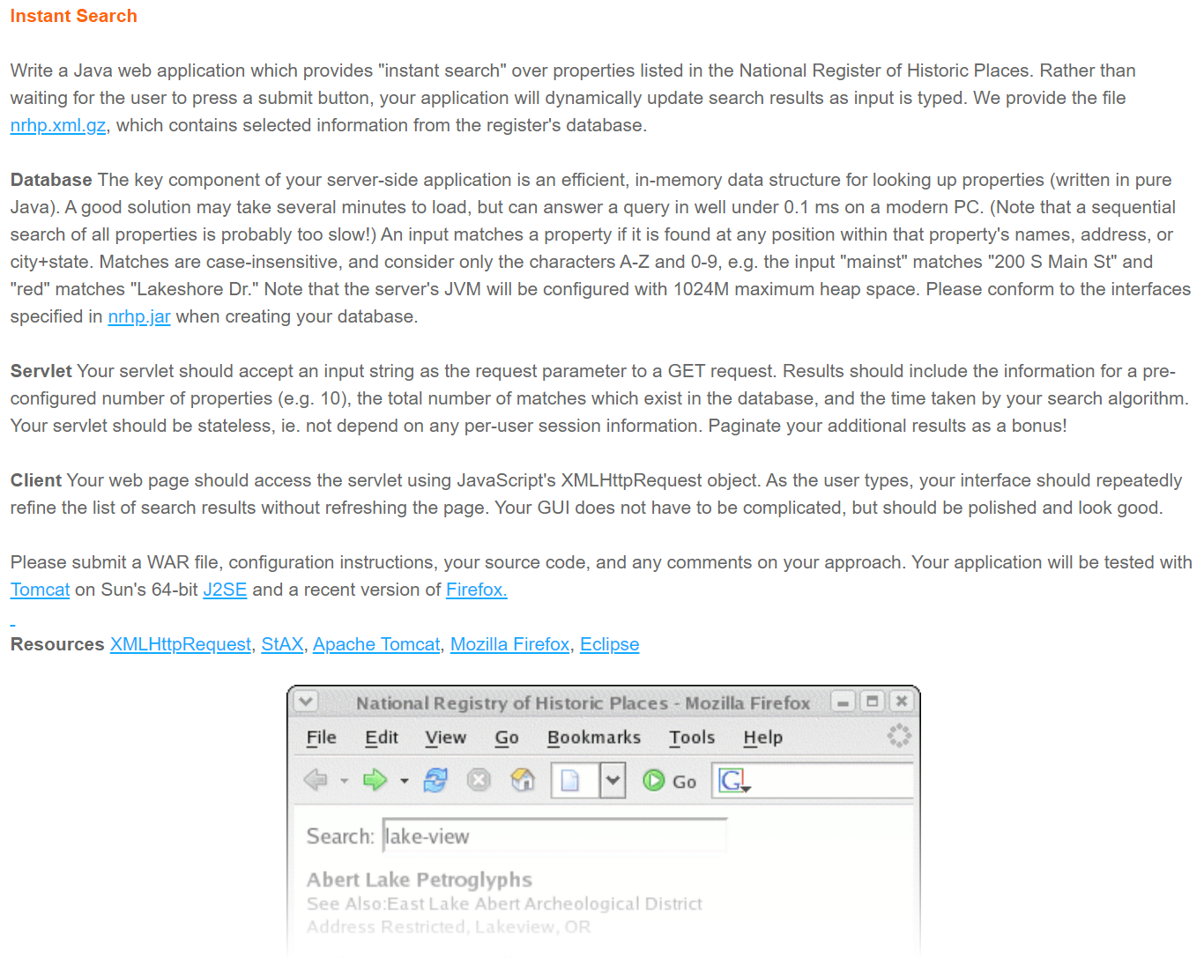
Instant Search
Write a Java web application which provides “instant search” over properties listed in the National Register of Historic Places. Rather than waiting for the user to press a submit button, your application will dynamically update search results as input is typed. We provide the file
nrhp.xml.gz, which contains selected information from the register’s database.Database The key component of your server-side application is an efficient, in-memory data structure for looking up properties (written in pure Java). A good solution may take several minutes to load, but can answer a query in well under 0.1 ms on a modern PC. (Note that a sequential search of all properties is probably too slow!) An input matches a property if it is found at any position within that property’s names, address, or city+state. Matches are case-insensitive, and consider only the characters A-Z and 0-9, e.g. the input “mainst” matches “200 S Main St” and “red” matches “Lakeshore Dr.” Note that the server’s JVM will be configured with 1024M maximum heap space. Please conform to the interfaces specified in
nrhp.jarwhen creating your database.Servlet Your servlet should accept an input string as the request parameter to a GET request. Results should include the information for a pre-configured number of properties (e.g. 10), the total number of matches which exist in the database, and the time taken by your search algorithm. Your servlet should be stateless, ie. not depend on any per-user session information. Paginate your additional results as a bonus!
Client Your web page should access the servlet using JavaScript’s XMLHttpRequest object. As the user types, your interface should repeatedly refine the list of search results without refreshing the page. Your GUI does not have to be complicated, but should be polished and look good.
Please submit a WAR file, configuration instructions, your source code, and any comments on your approach. Your application will be tested with Tomcat on Sun’s 64-bit J2SE and a recent version of Firefox.

Client
I started building this from the UI down. The puzzle brief mentioned using XMLHttpRequest, so I avoided using any client-side libraries (the functionality I was asked to build on the client was, after all, quite simple). The screenshot included with the puzzle brief included just a text field for the search query and a list of results.
I wrote a function to listen for key presses, dispatch an asynchronous call to the server and render the response as soon as it came back. By 2011, I had been coding web applications for a while and I was able to implement that functionality in less than an hour of work.
Web application and Servlet code
The Servlet layer was also quite simple, since all it had to was handle an incoming XML request and dispatch it to what the brief called a database. Again, less than an hour of work here.
At this level, I also wrote code to parse the database of strings to index from an XML file containing data from the National Register of Historic Places. The Tomcat server would run this code when loading my web application and use the resulting data to construct a data structure to use as an index for power the fast search functionality I needed to build. I needed to figure that out next.
Finding a suitable data structure
This is, unsurprisingly, the most challenging part of the puzzle and where I focused my efforts the most. As pointed out in the problem description, looping sequentially through the list of landmarks would not work (it would take much longer than the target 0.1ms threshold). I needed to find data structure with good runtime complexity associated with lookup operations.
I spent some time thinking about how I would implement a data structure allowing the fast lookup times required in this case. The most common fast-lookup option I was familiar with, the hash table, would not work straight away with this problem because it would expect the search operation to have the full key string. In this problem, however, I wanted to be able to look up entries in my index even when given an incomplete substring, which would have required me to store all possible substrings as keys in the table.
After doing some sketching on paper, it seemed reasonable to expect that tries would work better here.
Suffix trees
As I was researching data structures providing fast lookup operations given partial strings, I stumbled upon a number of papers referencing suffix trees, commonly used in computational biology and text processing, offering lookup operations with linear runtime with respect to the length of the string to search for (as opposed to the length of the string to search within).

Plain suffix trees, however, are designed to find matches of a given candidate string sequence within a single, longer, string, while this puzzle revolved around a slightly different use case: instead of having a single long string to look up matches in, I needed to be able to find matches in multiple strings. Thankfully, I read some more and found a good number of papers documenting data structures called generalized suffix trees that do exactly that.
Based on what I had learned so far, I was convinced this type of tree could fit my requirements but I had two likely challenges to overcome:
- Suffix trees tend to occupy much more space than the strings they are indexing and, based on the problem statement, “the server’s JVM will be configured with 1024M maximum heap space” and that needed to accommodate the Tomcat server, my whole web application and the tree I was looking to build.
- Much of the complexity of working with suffix tree lies in constructing the trees themselves. While the puzzle brief was explicitly saying my solution could take “several minutes to load”, I did not want the reviewer of my solution to have to wait several hours before they could test my submission.
Ukkonen’s algorithm for linear runtime tree construction
Thankfully, had I found a popular algorithm for generating Suffix Trees in linear time (linear in the total length of the strings to be indexed), described by Ukkonen in a paper published in 1995 (On–line construction of suffix trees).
It took me a couple days of intermittent work (remember: I was working on this during nights and weekends — I had another day job back then) to get my suffix tree to work as expected.
Interestingly, some of the challenges with this stage were revolving around a completely unexpected theme: Ukkonen’s paper includes the full algorithm written in pseudo-code and good prose detailing the core steps. However, that same pseudo-code is written at such a high level of abstraction that it did take some work to reconduct it to fast and efficient Java code.

Also, the pseudo-code algorithm is written assuming we are working with a single string represented as a character array, so many of the operations outlined there deal with indices within that large array (e.g. k and i in the procedure above).
In my Java implementation, instead, I wanted to work with String objects as much as possible. I was driven by a few different reasons:
- Java implements string interning by default — there is no memory benefit in representing substrings by manually manipulating indices within an array of characters representing the containing string: the JVM already does that transparently for us.
- Working with
Stringreferences led to code that was much more legible to me. - I knew my next step would be to generalize the algorithm to handle building an index on multiple strings and that was going to be much more difficult if I had to deal with low level specifics about which array of character represented which input string.
Generalized Suffix Trees
This last consideration proved to be critical: generalizing the suffix tree I had up to this point to work with multiple input strings was fairly straightforward. All I had to do was to make sure the nodes in my tree could carry some payload denoting which of the strings in the index would match a given query string. This stage amounted to a couple hours of work, but only because I had good unit tests.
At this point, things were looking great. I had spent maybe a couple days reading papers about suffix trees and another couple days writing all the code I had so far. I was ready to try out running my application with the input data provided with the puzzle brief: the entire National Register of Historic Places, an XML feed totaling a few hundred megabytes.
Trial by fire: OutOfMemoryError
The first run of my application was disappointing. I started up Tomcat and deployed my web application archive, which triggered parsing the XML database provided as input and started to build the generalized suffix tree to use as an index for fast search. Not even two minutes into the suffix tree construction, the server crashed with an OutOfMemoryError.
The 1024 megabytes I had were not enough.
Thankfully, a couple years earlier I had worked with a client that had a difficult time keeping their e-commerce site up during peak holiday shopping season. Their servers kept crashing because they were running out of memory. That in turn led me to learn how to read and make sense of JVM memory dumps.
I never thought I would make use of that skill for my own personal projects but this puzzle proved me wrong. I fired up visualvm and started looking for the largest contributors to memory consumption.
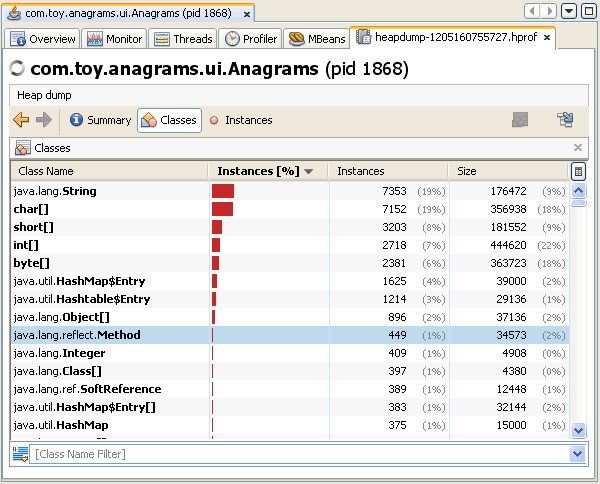
It did not take long to find that there were a few memory allocation patterns that were not efficient. Many of these items would hardly be an issue for an average application, but they all ended up making a difference in this case because of the sheer size of the tree data structure being constructed.
Memory micro-optimizations
Analyzing a few heap dumps suggested me a series of possible changes that would lead to savings in memory, usually at the cost of additional complexity or switching from a general purpose data structure implementation (e.g. maps) to special purpose equivalent tailored to this use case and its constraints.
I ranked possible optimizations by their expected return on investment (i.e. comparing value of the memory savings to the additional implementation complexity, slower runtime and other factors) and implemented a few items at the top of the list.
The most impactful changes involved optimizing the memory footprint of the suffix tree nodes: considering my application required constructing a very large graph (featuring tens of thousands of nodes), any marginal savings coming from a more efficient node representation would end up making a meaningful difference.
A property of suffix tree nodes is that no outgoing edges can be labeled with strings sharing a prefix. In practice, this means that the data structure implementing a node must hold a reference to a set of outgoing edges keyed by the first character on the label.
The first version of my solution was using a HashMap<Character,Edge> to represent this. As soon as I looked at the heap dump, I noticed this representation was extremely inefficient for my use case.
Hash Maps in Java are initialized with a load factor of 0.75 (meaning they generally reserve memory for at least 25% more key/value pairs than they hold at any given point) and, more importantly, with enough initial capacity to hold 16 elements.
The latter item was a particularly poor fit for my use case: since I was indexing strings using the English alphabet (26 distinct characters) a map of size 16 would be large enough to accommodate more than half the possible characters and would often be wasteful.
I could have mitigated this problem by tuning the sizing and load factor parameters but I thought I could save even more memory by switching to a specialized collection type. The default map implementations included in the standard library require the key and value types to be reference types rather than native types (i.e. the map is keyed by Character instead of char) and reference types tend to be much less memory efficient (since their representation is more complex).
I wrote a special-purpose map implementation, called EdgeBag, which featured a few tweaks:
- stored keys and values and two parallel arrays,
- the arrays would start small gradually grew if more space if necessary,
- relied on a linear scan for lookup operation if the bag contained a small number of elements and switched to using binary search on a sorted key set if the bag had grown to contain more than a few units,
- used
byte[](instead ofchar[]) to represent the characters in the keys. Java’s 16-bitchartype takes twice as much space as abyte. I knew all my keys were ASCII characters, so I could forgo Unicode support here and could squeeze some more savings by casting to a more narrow value range.
Some more specific details on this and other changes to reduce the memory footprint of my suffix tree implementation are in the Problem-specific optimizations section of the Suffix Tree project page.
Conclusion
When I tested out my program after the memory optimizations, I was delighted to see it met the problem requirements: lookups were lightning fast, well under 0.1ms using the machine I had back then (based on an Intel Q6600 2.4GHz CPU) and the unit tests I had written gave me good confidence that the program behaved as required.
I packaged up the solution as a WAR archive, wrote a brief README file outlining design considerations and instructions on how to run it (just deploy on a bare Tomcat 6 server) and sent it over email. Almost a year later, I was packing my bags and moving to Amsterdam to join Google (which had by then acquired ITA Software).
I owe it in no small part to the fun I had with this coding puzzle.
When I think of how much I enjoyed the time I spent building Instant Search, I think it must be because it required both breadth (to design a full stack application, albeit a simple one) and depth (to research the best data structure for the job and follow up with optimizations as required). It allowed me to combine my background as a generalist with my interest with the theoretical foundations of Computer Science.
The careful choice of specifying both memory and runtime constraints as part of the problem requirements made the challenge much more fun. When the first version I coded did not work, I was able to reuse my experience with memory profiling tools to identify which optimizations to follow up with. At the same time, I built a stronger understanding of Java’s internals and learned a lot more about implementation details I had, until then, just given for granted.
When ITA retired Instant Search (and other programming puzzles1), I decided to release the Java Generalized Suffix Tree as open source for others to use. Despite the many problem-specific optimizations I ended up making, it is generic enough that has been used in a few other applications since I built it, which gives me one more thing to be thankful for.
Footnotes
While the original page is no longer online, the Wayback Machine still has a snapshot of the original page with the original selection of past programming puzzles. They are still a great way to test your programming skills. ↩