• Coding • 26 min read
The nearest hospital to every place on Earth, in a single S2 range query
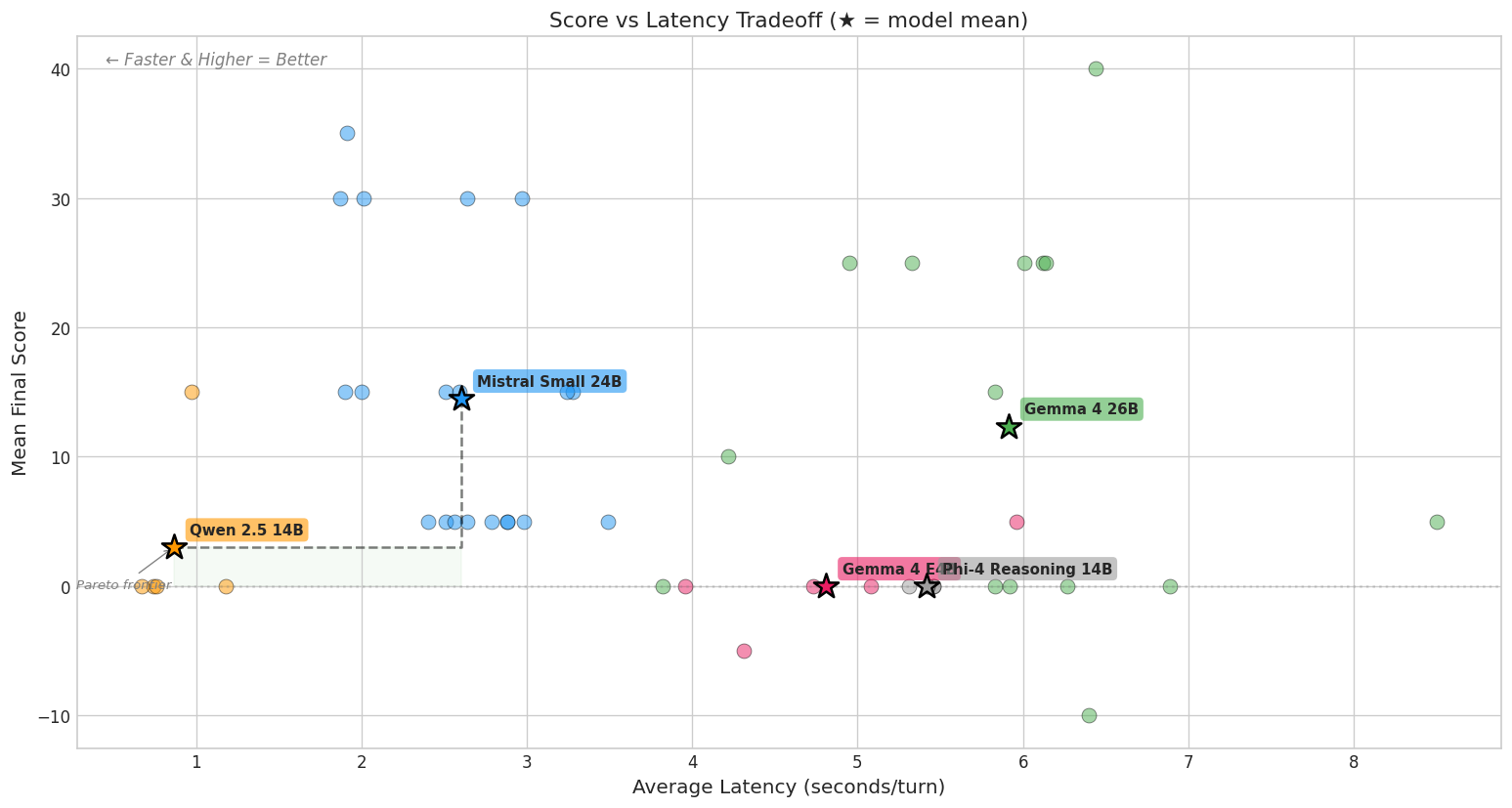
For every locality on Earth, how far is the nearest hospital? Naively, that's 437 billion great-circle distances. S2 cell indexing reduces it to a single integer range-join: build the index once, and the answer for every place on Earth comes back in seconds. The same primitive also resolves which country, region, and locality each hospital belongs to, in a single pass over one index.